
Table of Contents
You can read this Deep Dive or enjoy a podcast style version voiced by the writer’s AI twin and guest co-presenter.
Big Picture Scene Setting
Looking through the lens of operational leadership, there are ongoing implications as AI is progressively integrated into everyday life. We are a transitional generation. Pivoting from a familiar way of working to something still being formed.
Such is the volume of new things to think about and act on, we are having to learn about things we could have once left to our technically minded colleagues. What was fringe to a successful career is now core. It seems everyone now needs their own foundation understanding of AI to remain part of what’s next.
The mission is simply this.
We’re being enlisted into a collective effort to reinvent our organisations. To figure out through trial and significant error, when and if AI makes sense. And of course, ensure progress is being made before others race too far ahead.
In this context, informed decision-making needs foundation understanding rather than narrow up-skilling in what’s a rapidly evolving set of technologies.
A foundation approach offers broader benefits. Such as understanding how to mitigate the key risks and therefore protect your ability to realise the benefits. Or put more bluntly: not allow ignorance of the downsides to screw up your investment in realising the upsides.
Here’s another important benefit. Having a foundation understanding of how Large Language Models (LLMs) behave, allows you to distinguish ‘the art of the possible’ from ‘a hope for the impossible’.
To put this into context, let’s think about one of LLMs better known behaviours – the tendency to ‘hallucinate’. What’s your understanding of this behaviour? Are you a ‘comes with the territory’ type of person? Or are you mystified by the very concept!! As in, ‘is psychotropic artificial intelligence even a thing!’?
Having clear understanding of whether you can ever expect to completely remove hallucinations from LLM behaviour does matter. It influences if, when, and how you deploy them, and sets expectations for their management.
Understanding LLM Hallucinations
Hallucinations occur when a model generates information that is false, misleading, or unsupported by facts, while presenting it as truthful and accurate.
These hallucinations can range from minor inaccuracies to completely fabricated information. In customer service contexts, this might manifest as an AI agent providing incorrect product details, misquoting company policies, inventing non-existent services.

This is the headline from a May 2025 article in the New York Times. This is how it starts.
Last month, an A.I. bot that handles tech support for Cursor, an up-and-coming tool for computer programmers, alerted several customers about a change in company policy. It said they were no longer allowed to use Cursor on more than just one computer.
In angry posts to internet message boards, the customers complained. Some canceled their Cursor accounts. And some got even angrier when they realized what had happened: The A.I. bot had announced a policy change that did not exist.
“We have no such policy. You’re of course free to use Cursor on multiple machines,” the company’s chief executive and co-founder, Michael Truell, wrote in a Reddit post. “Unfortunately, this is an incorrect response from a front-line A.I. support bot.”
Here’s a healthcare example from another article.
According to The New York Times which reported the story, the AI in question, ‘drafted a message reassuring a patient she had gotten a hepatitis B vaccine‘. When in fact, the patient’s records showed ‘no evidence of that vaccination’.
Might this have life-threatening consequences? Maybe not. But is certainly one that undermines the health provider’s reputation.
Now, you might hear this with enough foundation understanding to immediately wonder why the LLM was not plumbed into an approved source of patient information. Or ask why human oversight was not embedded into the patient communication workflow.
In which case, as a leader in that healthcare provider, your issue is not your own level of understanding. But that of others who fell short of recognising the risks. Or maybe just finding someone with enough know-how to troubleshoot and report back to you if the incident was one-off or systemic.
Alternatively, if the story did surprise you, here’s some relevant foundation understanding to absorb.
‘Human intelligence’ and ‘artificial intelligence’ are not the same. Even though you’ll find this assumption frequently restated in a variety of ways across social media and broadcasting. Therefore, In the absence of any well-publicised, contrary view, it’s easy to end up believing that artificial intelligence is basically the same as our own.
But the differences are crucial to understand.
As a Large Language Model generates output, it is not consciously aware of ‘right’ versus ‘wrong’ answers as a human mind is. Instead, it is predicting what to say next based on statistical probabilities. These are shaped by the completeness and accuracy of its training data and the way in which the model is designed, built and optimised.
It is also important to appreciate AI’s lack of adaptability relative to our own. Humans excel at adapting to new situations and contexts. Often with little to no conscious effort.In contrast, Machine Learning and Deep Learning experts will tell you that choosing the right class of model is crucial. ‘Best fit’ is based on what each type of model is optimised to excel in.
Unsurprisingly, this principle applies to Large Language Model choices as well. This means a great model will underperform when picked for the wrong job. In other words, the use case directly influences the quality of outcome.
As evidence of this, Stanford researchers have found that, even though fine-tuned, legal advice models still hallucinate in about one out of six queries, which is roughly 16% of the time. this still compares favourably against ‘general purpose’ models. These ones showed failures rates above 50% when tasked with answering legal questions.
It’s back to an old truth. Choosing the right tool matters.
As an operational leader, you should not expect yourself to be qualified to make such choices – unless you choose to ‘go geek’ – All you need is enough understanding that it’s ‘a question that needs raising’ and ‘a choice that needs making’.
Just keep in the back of your mind that LLMs are not created equal. Nor are the latest releases a guarantee of reduced hallucinations: simply because the context of their use is a huge influence on their effectiveness.
This is why organisations need to be actively aware of which LLMs they currently deploy, are about to deploy, and how they are being used.
Unfortunately, tracking them can be opaque. Especially when bundled into larger solutions such as CCaaS (call centre as a service) or the incoming wave of AI agent solutions.
Here’s a visual from the AI For Non Technical Minds course that’s illustrates the issue.
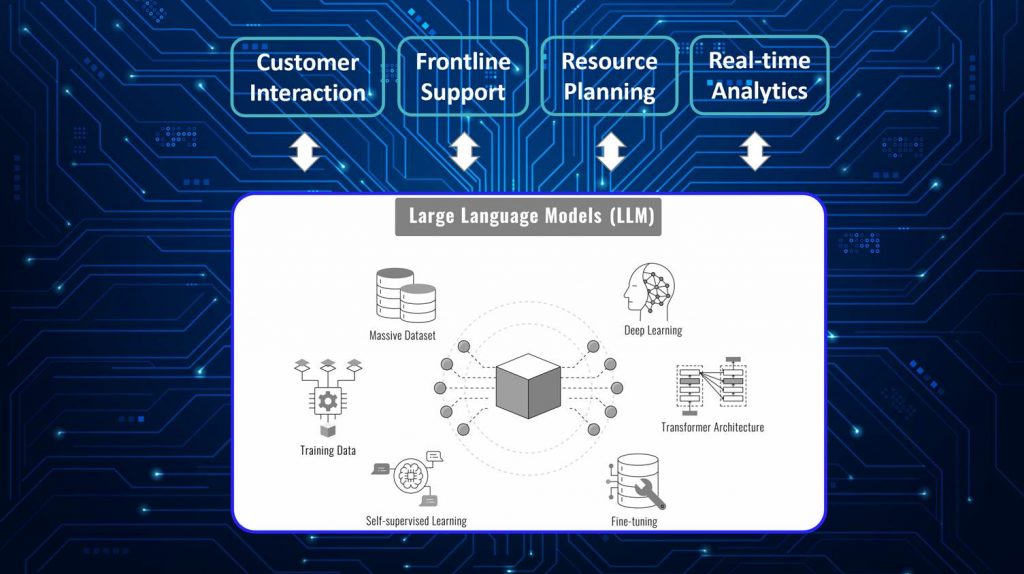
LLM Governance
Why does this matter to customer service leaders? It matters because Large Language Models increasingly drive today’s customer service infrastructure. Vendor competition to be first to market with the next ‘bigger-better’ AI capability has been intense ever since day one of Generative AI’s premature market release: which is another story for another time.
As a result, every category, from omni-channel orchestration to real-time conversation intelligence, is now infused with LLM goodness as the visual shows. It turns out that ‘finding patterns in large datasets in real-time’, and ‘what contact centres churn out by the bucketload each day’, makes for a ‘perfect marriage’.
So far, results are encouraging. But given everything just said about hallucinations, what unfamiliar threats might service leaders now face from LLMs?
The trouble is you need to poke around quite a bit to find out. Contact centre solution providers seldom, if ever, develop their own Large Language Models given the expense and expertise required.

It’s an intensively competitive space that needs deep pockets. One in which next generation models are launched at breakneck speed in the race to be first. One that is now evolving into a quest for supremacy in Agentic AI which takes the art of generation into the world of execution.
Do you imagine that contact centre vendors or their channel partners know much about these Large Language Models? Obviously their in-house solution designers do since they have to select the best ones to integrate. And to be clear, I’m not suggesting that bad choices are being made.
But Large language models remain ‘black boxes’ in terms of how they work – even to their original designers and the broader research community that investigates them. To massively understate the challenges involved, making the inner workings of a published model ‘transparent’ and ‘adaptive’ remains work in progress. In fact, we have scarcely got going.
This prompts the question whether you and your organisation are taking too much on trust.
Why?
We know models behave differently across generations: given ‘design tweaks’ and ‘fine- tuning’ in the quest to reach the next competitive breakthrough. Might a new version therefore impact previously reliable behaviour?
Is it unreasonable to assume contact centre vendors will be drawn or nudged towards embedding the latest version to stay ahead? Cloud solutions are constantly being iteratively improved. It’s a core feature. If that’s the case, what are the risks of introducing a new LLM? As said earlier, it’s best to understand the downsides to protect the upside benefits.
The problem is, what does the typical operational leader in customer service actually know about any of this?
Has anyone thought to ask which models are being used? Whether they were tested against specific use cases in customer service; for your sector’s needs, and potentially for any regulatory demands? Testing all that is a time commitment that’s not so easy when it’s a race to be first.
Also, these questions might need to be directed at a single partner solution. Or more likely, be directed towards the full mix of vendors that make up your customer service ecosystem.
And it is highly unlikely, that in such a young market, there is even the notion, as yet, of a commonly accepted testing framework or set of standards.
But putting that to one side, let’s assume that sufficient due diligence is taking place. Are the results being shared with you?
You and your team need that insight to ensure their effective supervision and management. No LLM is perfect. They hallucinate, exhibit bias, and can behave in other unexpected ways.
But hampered by a lack of foundation understanding, we’ve learnt to believe in a trinity of safeguards that we were asked to take on trust: guardrails, fine tuning, and of course RAG.
As a side note: RAG or Retrieval-Augmented Generation, is a technique that enhances LLMs by integrating them with quality-controlled data sources such as a curated in-house knowledge base. This enables them to provide more accurate and contextually relevant responses.
The combined impact of guardrails, fine tuning, and RAG is that hallucinations are certainly reduced. But are not eliminated.
And to be clear you should assume they never will be.
“Despite our best efforts, they will always hallucinate,” said Amr Awadallah, the chief executive of Vectara, a start-up that builds A.I. tools for businesses, and a former Google executive. “That will never go away.”
If you take that advice on board shouldn’t ‘passive acceptance’ convert into proactive risk management dialogue and action? Isn’t it best to adopt a mindset of ‘Trust But Verify’, and start to ask more penetrating questions next time your vendor’s customer success team visits?
In anticipation, here’s a framework to guide that discussion you can adapt to your own needs and circumstances. You can also download this as a pdf for internal distribution at the end of this deep dive.
As you will notice, the scope of discussion is greater than just hallucination. It is part of your broader governance to ensure effective operational use and quality assurance of LLMs as they are currently deployed in customer engagement. And in the emerging context of AI worksflows and Multi Agent Systems in which LLMs will continue to play a vital role.
LLM Identification and Provenance
- Of the solutions that we purchase from you, which specifically use LLMs?
- Who produces these LLMs (e.g., OpenAI, Google, Anthropic, open-source, proprietary)?
- What specific model/version are we currently using (e.g., GPT-4, Claude 3, Llama 3)?
- Have these models been additionally modified: fine-tuned, prompt-engineered, RAG-enabled, or customised?
- If modified, please specify how, why, and by whom these modifications were made
- Do you provide model cards or documentation detailing model specifications, training data sources, and known limitations?
Governance and Upgrade Management
- What’s your policy and process for model upgrades and version management?
- How do we collaborate on early visibility, testing, and establishing acceptance criteria?
- What is your change management process for LLM updates?
- Do you maintain previous versions if new ones prove problematic?
- How much notice do clients receive before updates are implemented?
- Is there a sandbox/staging environment where we can test new models before production deployment?
- Can we opt out of automatic upgrades if necessary for compliance or operational reasons?
LLM Selection and Evaluation Criteria
- What criteria do you use to select the appropriate LLM for specific use cases?
- How has it been tested to verify suitability for contact center applications?
- Do you conduct comparative evaluations across different models for each use case?
- What performance benchmarks do you use to evaluate model effectiveness?
- Can you provide case studies or examples specific to our industry/use case?
- What are the known limitations of the selected models for our specific requirements?
- Do you support candidate model architecture allowing customers to swap the LLM behind specific use cases?
Hallucination Mitigation Strategies
- What specific measures have you implemented to reduce or mitigate LLM hallucinations in your CCaaS solution?
- What structured output generation techniques do you employ?
- How do you enforce strict rules for LLM outputs?
- What system prompt enhancements have you implemented?
- Do you utilise retrieval-augmented generation (RAG) or semantic layer approaches?
- What’s your guidance on expected hallucination rates for different contact centre functions?
- What’s your specific advice for the use cases we want to implement?
- Are there specific domains or topics where your LLMs are more prone to hallucinations?
Performance Monitoring and Benchmarking
- What performance data can you share with us on hallucination rates and other quality metrics?
- Is this data historical or continuously updated?
- Do you have specific performance data aligned with our industry and use cases?
- How can we collaborate on data sharing and establishing our own benchmarks?
- What reporting tools do you provide for ongoing performance monitoring?
- Do you offer reportable reasoning that explains why the AI reached specific conclusions?
- What KPIs do you recommend for monitoring LLM performance in contact centre applications?
- How do you measure and report on AI-specific metrics beyond traditional contact centre metrics?
Risk Management and Operational Controls
- What capabilities do you provide to help us manage LLM risks throughout the lifecycle?
- What pre-launch testing tools or procedures do you recommend?
- What operational management and reporting capabilities are available?
- How can we optimise performance over time?
- Do you provide real-time monitoring for LLM outputs?
- What fail-safe mechanisms exist when LLMs operate beyond their knowledge limits?
- What escalation paths exist for handling problematic AI outputs?
- Do you offer human-in-the-loop options for high-risk scenarios?
Training and Knowledge Transfer
- What training or guidance do you provide to help our staff effectively use and oversee LLM-powered features?
- Do you offer role-specific training for advisors, supervisors, and administrators?
- What documentation is available for troubleshooting LLM-related issues?
- Do you provide best practice guides for prompt engineering or system optimisation?
- What ongoing education do you offer as models evolve?
- How do you support change management during implementation?
- Do you offer certification programs for staff managing LLM-powered tools?
Data Privacy and Security
- What data privacy and security measures do you have in place for your LLM implementations?
- What customer data is used for training, fine-tuning, or inference?
- How is sensitive customer information protected during LLM processing?
- What data residency guarantees can you provide?
- How do you prevent data leakage between different customers’ environments?
- What security testing has been conducted on your LLM implementation?
- Can you provide a private instance back-end where we can plug in our own LLMs?
- What measures are in place to prevent unauthorised access to training data?
Compliance and Regulatory Considerations
- How do you ensure compliance with relevant AI regulations and standards?
- Which AI governance frameworks do you adhere to – NIST [cyber], EU AI Act, etc.?
- Have your LLM implementations undergone third-party audits or certifications?
- How do you address emerging requirements like OWASP Top 10 for LLM Applications? – the most critical security risks to web applications
- What documentation can you provide to support our compliance obligations?
- How do you handle international data sovereignty requirements?
- What is your approach to AI transparency and explainability requirements?
- Can you provide AI FactSheets or Declarations of Conformity?
Integration and Technical Architecture
- How are LLMs technically integrated within your CCaaS platform?
- Do you use retrieval-augmented generation (RAG) or other architectural approaches?
- What APIs or integration points are available for customisation?
- How do LLM components interact with other platform features?
- What latency considerations should we be aware of?
- How do you handle service disruptions or outages in underlying LLM services?
- What cloud infrastructure requirements exist for optimal performance?
- What is your approach to extensibility and customisation?
Cost Management and Optimisation
- What is your pricing and cost structure for LLM-powered features?
- How do you optimise costs while maintaining performance?
- Are there variable costs that could lead to pricing unpredictability?
- What cost-control mechanisms are available to manage LLM usage?
- How do you handle high-volume scenarios from a cost perspective?
- What ROI metrics or case studies can you share from similar deployments?
- Do you offer cost analysis tools to optimise spend?
Support and Service Level Agreements
- What support do you provide specifically for LLM-powered features?
- What are your SLAs for addressing LLM-related issues?
- Do you have specialised support staff with AI/ML expertise?
- What ongoing optimisation services do you offer?
- How do you communicate about emerging risks or issues?
- What level of professional services support is available for custom model fine-tuning?
- How are issues escalated when LLM performance falls below expectations?
Future Roadmap and Innovation
- What is your roadmap for LLM implementation in your CCaaS solution?
- How do you evaluate and incorporate emerging LLM technologies?
- What upcoming features or improvements can we expect?
- How do you balance innovation with stability and reliability?
- What customer feedback mechanisms influence your LLM development?
- How can we participate in your beta programs for new AI capabilities?
- What research partnerships do you maintain with academic or industry AI leaders?
Remember, your purpose is to assess the level of risk you are inheriting and how that is balanced against the benefits brought by LLMs.
Also approach these sessions in the right spirit. They are going to work best as a collaborative rather than confrontational conversation.
Finally, be patient. It might take more than one session to get into the rhythm of productive discussion and ensure the right expertise is in the room.
Concluding Thoughts
Hallucinations are a feature of LLM technology until someone invents another architecture to enable generative AI. They can be reduced based on use case and various safeguards. But to answer the question posed in the tile of this deep dive ‘Are LlMs really a threat to your CX.
Being able to engage in discussion and decision-making on LLMs is becoming an operational responsibility: given the increasingly important role they are set to play in AI-first operating models: in which contact centres and customer service are early adopters. We intend the framework provided here will prove useful guidance for those discussions and decisions.
You can download the pdf version here and distribute it for internal use. This version has embedded links that define key terminology so it is recommended to ensure common foundation understanding for those leading and taking part in LLM governance discussions.
Thank you for your time and attention on this deep dive.